A Gamified Framework for Conflict-Driven Design
Collaborators: Jin Gao
ACADIA 2025 Conference
INTRODUCTION
In many design projects, one of the most challenging steps is reaching consensus, often shaped by negotiations and exchanges of interests among stakeholders.
Our research introduces a customized digital "board game" that provides a minimal abstraction of the real-world city-building process by modeling core stakeholder personas, their roles, and interactions. Within this environment, we apply multi-agent reinforcement learning (MARL) to train AI agents to develop strategies for resource allocation under competing objectives.
Related Work
Board games have long been established as participatory tools. In the board game community, city building is an important genre, exemplified by games such as Bay Area Regional Planner, Small Cities, and Suburbia. Serious games are also widely used in academic research (Poplin, 2012; Prasad et al., 2021), where interactive interfaces have emerged for participatory planning, bridging the gap between algorithmic optimization and public participation, such as CityScope (Alonso et al., 2018).
Game theory provides theoretical foundations in modeling and evaluating the decision process and equilibria. Prior studies have applied it to model land-use negotiations among stakeholders (Liu et al., 2016), and collective decision-making processes for urban planning (Abolhasani et al., 2022). These studies provide theoretical foundations for analyzing interdependent decision-making in urban contexts.
METHODS
Our method consists of three tightly coupled components:
- Game Environment: Simulates core stakeholder interactions and serve as a testbed for agents.
- MARL Workflow: Agents learn adaptive strategies under different value matrices.
- Digital Interface: Allows humans to observe and interact with agents during the decision process.
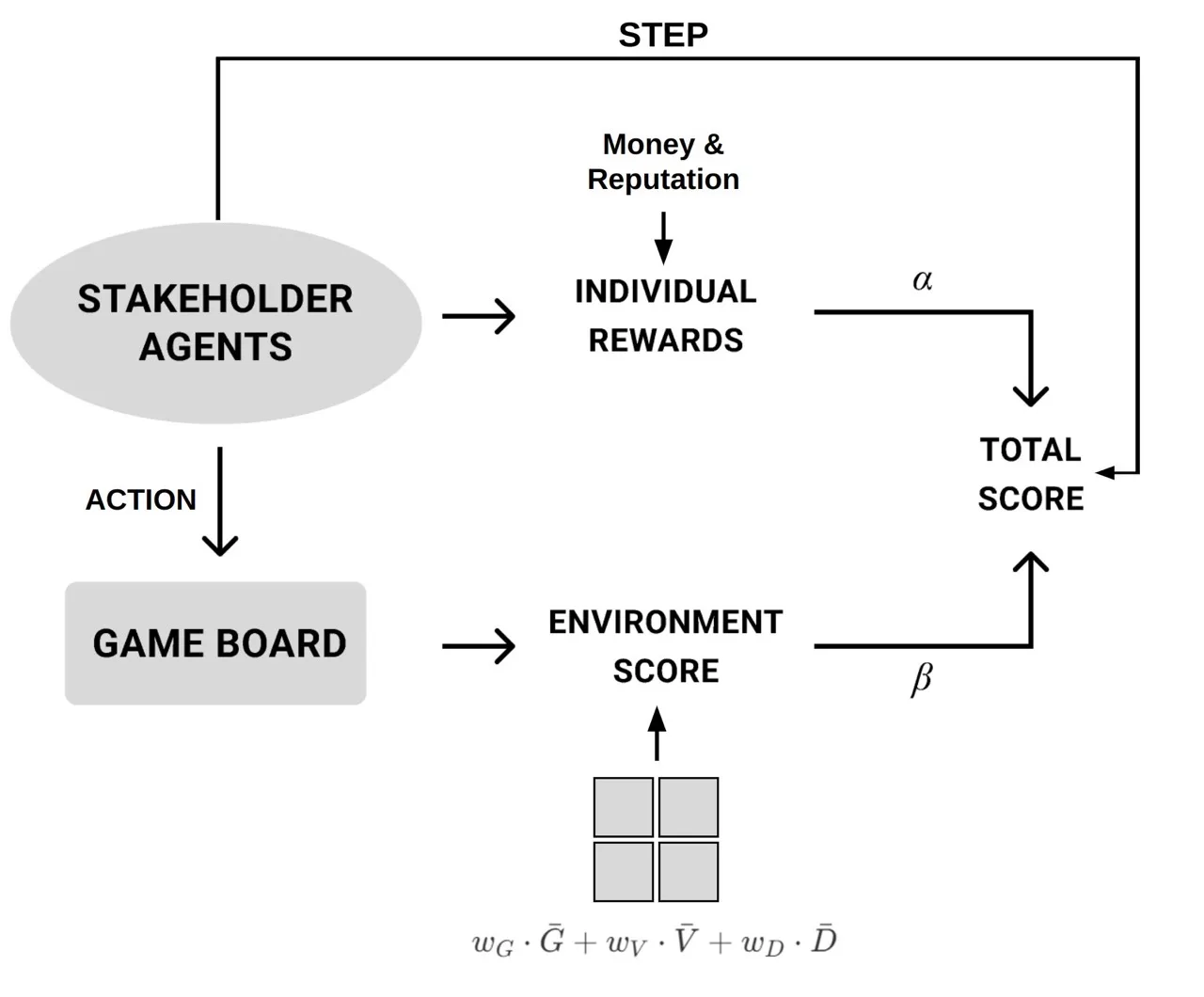
Environment
The game map consists of a configurable M × N grid. Each cell has key parameters representing environmental, economic, and social aspects. These are dynamically updated each round according to the buildings placed on the board.
We model stakeholder priorities using value matrices, where rewards balance self-interest against site conditions and resilience.
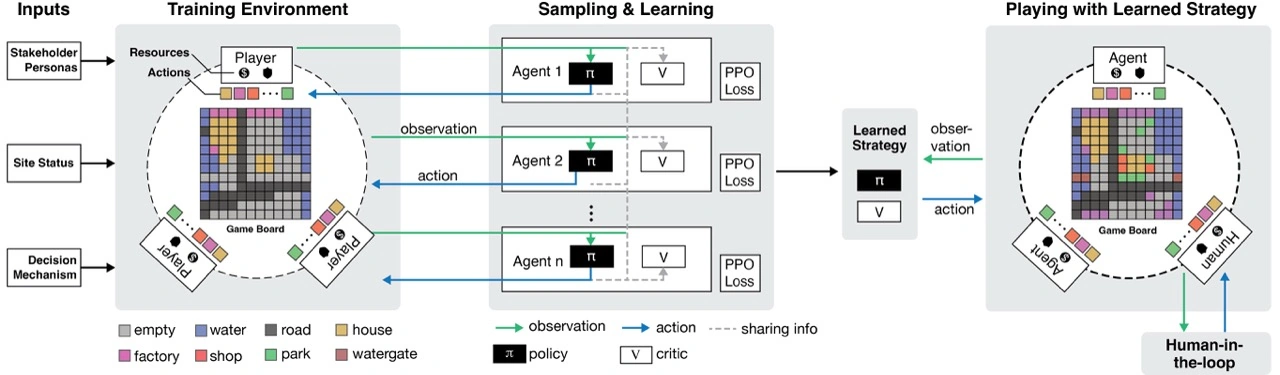
Multi-Agent Learning
Unlike zero-sum games, our environment is non-zero-sum. Stakeholders have conflicting objectives, but their actions generate shared benefits or collective challenges.
We use Coarse Correlated Equilibrium (CCE) to find mutually beneficial strategy distributions from which no agent has an incentive to unilaterally deviate.
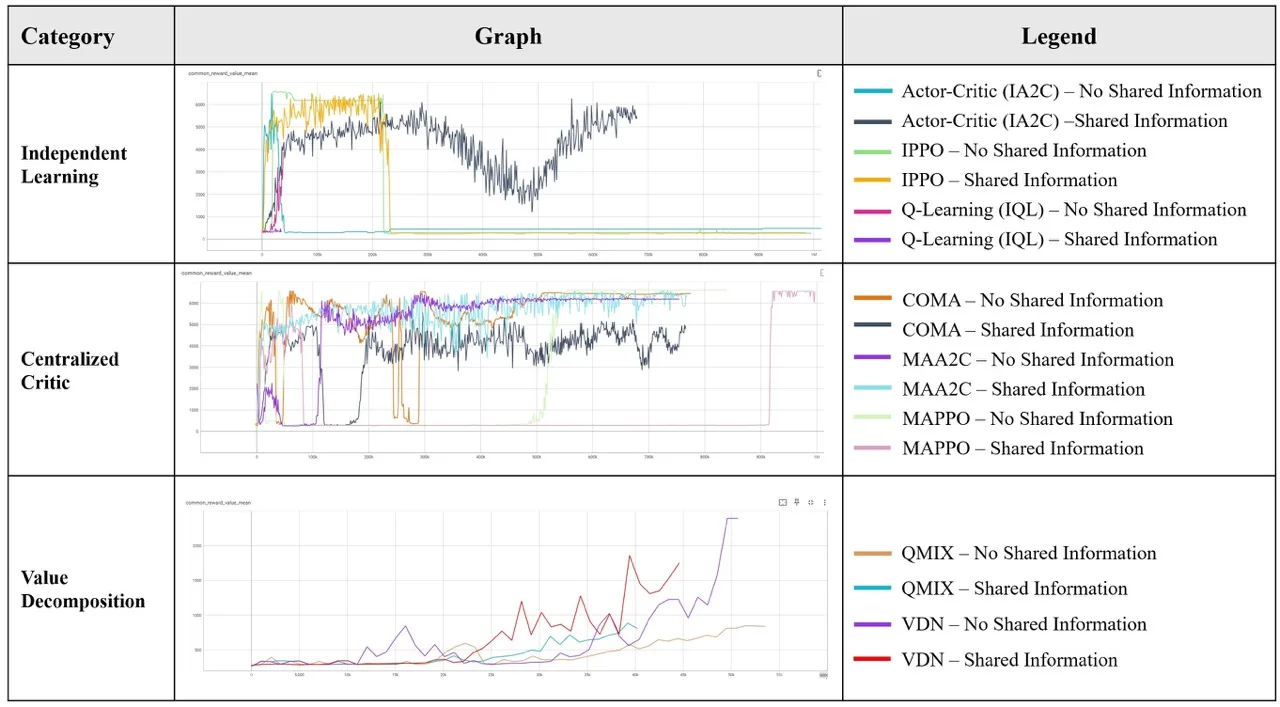
EXPERIMENTS
Proof of Concept & Scaled-up Results
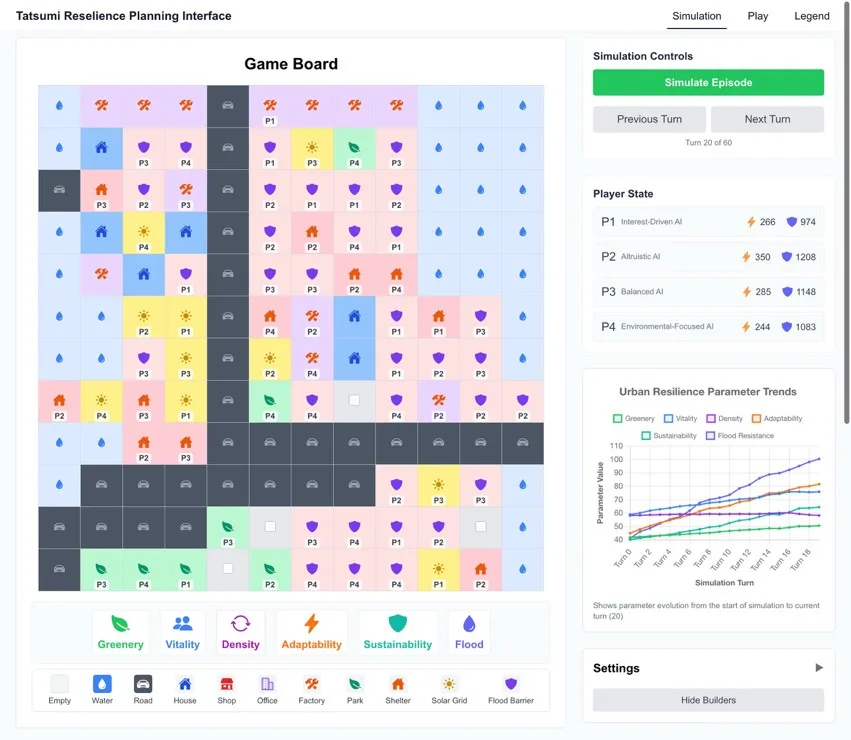
The Tatsumi Resilience Planning Interface is the digital front-end of our board-game environment. A grid-based map shows land-use tiles—housing, industry, parks, solar grids, flood barriers, and roads—each tagged with the agent (P1–P4) that placed or controls it. Alongside the board, Simulation controls let users step through episodes turn by turn or run a full 60-turn episode, while a Player State panel tracks four trained stakeholder personas (interest-driven, altruistic, balanced, and environmental-focused) with live resource and resilience scores. An Urban Resilience Parameter Trends chart plots Greenery, Vitality, Density, Adaptability, Sustainability, and Flood Resistance over time, making trade-offs between competing objectives visible as agents learn. Together, these views support human observation, replay, and human-in-the-loop play during participatory planning sessions.
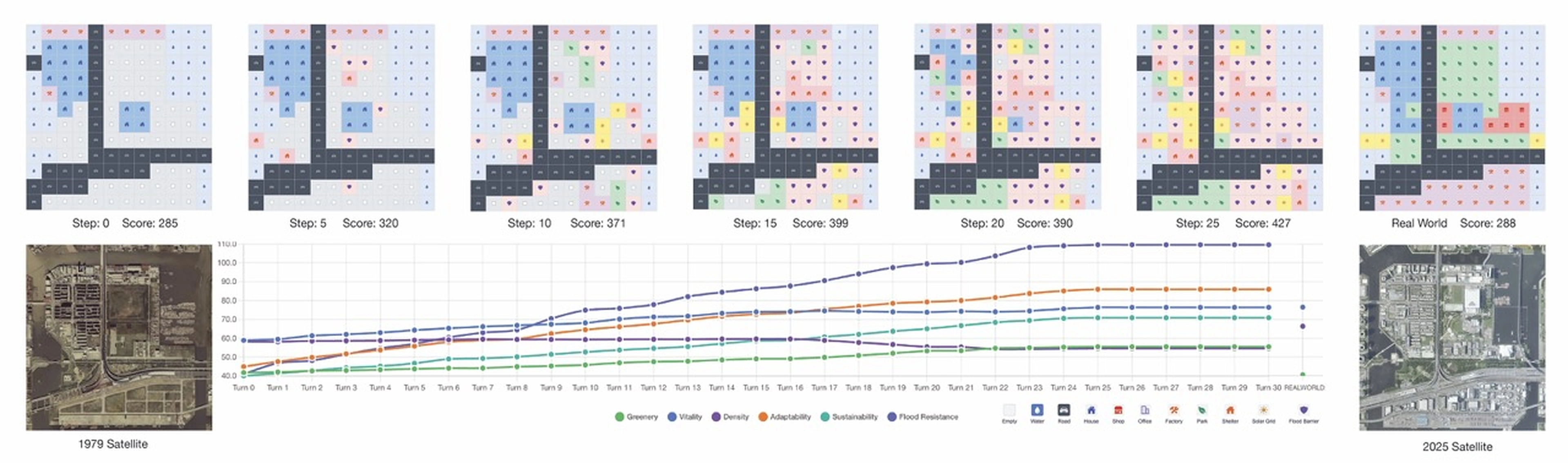
Applied Experiment in Tatsumi, Tokyo
We extend our model to a real-world site in Koto City, Tokyo, built on low-lying wetlands. A typical simulated game shows a 49% improvement compared to the baseline score on the 2025 real-world map, as agents learn to prioritize long-term resilience investments.

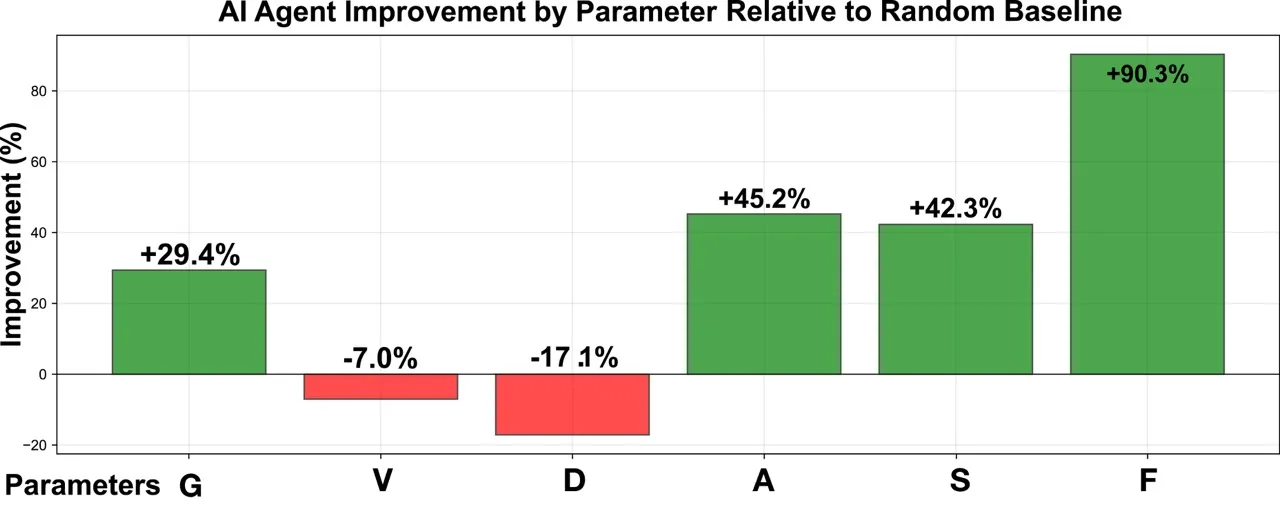
To rigorously assess the impact of our trained agents, we conducted 10,000 independent simulation runs against a random-policy baseline. Compared with the random baseline, the AI agents achieved a higher average total score (452.1, standard deviation (SD) = 3.2 vs. 357.3, SD = 16.0; p < 0.01) and a more concentrated distribution (interquartile range (IQR): 1.82 vs. 21.19). At the parameter level, the agents achieved substantial gains in resilience-related dimensions—Adaptability (A), Sustainability (S), and Flood Resistance (F)—while also improving Greenery (G). These advances indicate that the agents systematically learned to prioritize long-term resilience and adaptability.
CONCLUSION AND FUTURE WORK
This study presents a practical framework for modeling and evaluating the resource allocation process as a trainable digital board game, offering a novel bridge between game theory, multi-agent learning, and participatory planning. We capture the complex trade-offs between individual incentives and collective outcomes to maximize urban resilience through reward design. Notably, our scaled-up simulation shows that trained agents can learn to prioritize resilience-oriented projects while maintaining urban viability through self-play, forming context-aware, adaptive strategies through decentralized competition. The gamified environment serves not only as a learning substrate for agents but also as an interface for public engagement, supporting human-in-the-loop experimentation, which builds a foundation for explainable, interactive simulation with a focus on transforming how urban policy is prototyped and negotiated in future AI-augmented decision-making.
Several limitations remain. First, the reliance on an orthogonal grid restricts the ability to accurately capture irregular urban block structures. Second, the scoring system is based on predefined objective indices, which may oversimplify or misrepresent the nuanced trade-offs inherent in real-world decision-making. Third, reinforcement learning depends heavily on trial-and-error exploration, resulting in low training efficiency and potential instability or convergence challenges when scaling to larger environments and action spaces. More formal equilibrium evaluations are left for future work. Finally, although the framework provides an interactive interface that allows humans to observe and engage with the decision-making process, it has not yet incorporated full-scale human participant studies.
Looking ahead, future work will focus on scaling the environment and agent population to build a more robust pipeline under more complex and realistic conditions. Another direction is to integrate large language models to support human-interpretable reasoning processes and comprehensive chains of thought, incorporating real-life common sense and its influence on complex decision-making issues. Last but not least, the framework will be applied to real-world planning scenarios with human participants to explore its applicability in an AI-driven, participatory design process.