SentiScribe
Multimodal Fusion for Sentiment Analysis
System Description
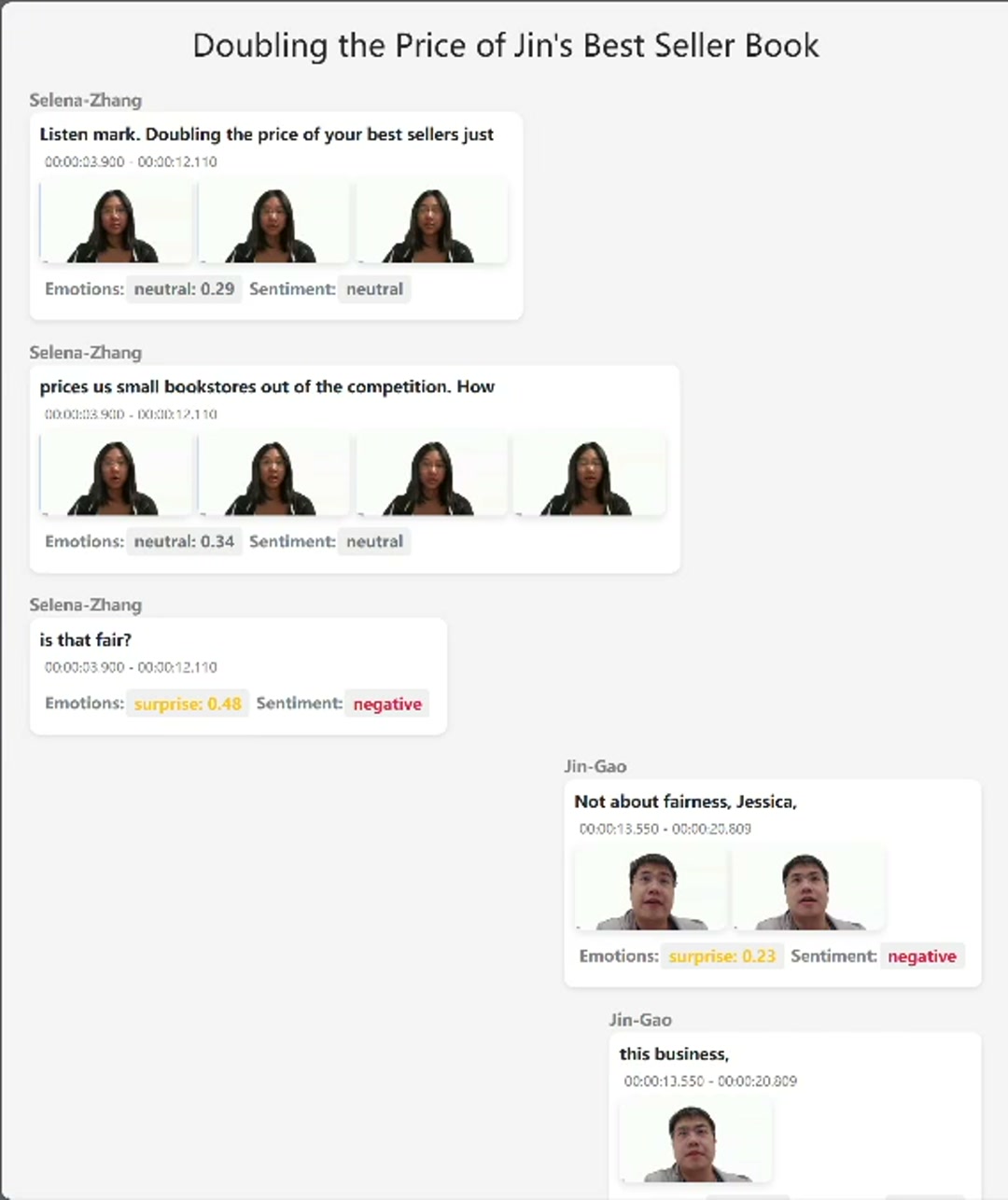
Our system takes as input a video file of a conversation, in which each speaker is visually present on screen when the audio of them speaking is playing.
Input Processing and Feature Extraction
In the first stage of our system, we processed the video by separating the audio waveform from the video and generating a text transcript. We then segmented the full video into sentence-level segments.
-
MELD Dataset:
- Provides video files and text transcripts already separated and segmented.
-
Zoom Data:
- Processed on a Macbook Pro 2019.
- A Zoom recording contains:
- An mp4 video file (maximum resolution: 720p, due to Zoom constraints and Macbook Pro 2019 camera).
- An m4a audio file.
- Zoom transcripts are already segmented into sentence-level blocks.
- We applied additional preprocessing to ensure that Zoom video segmentation matched the transcript segmentation.
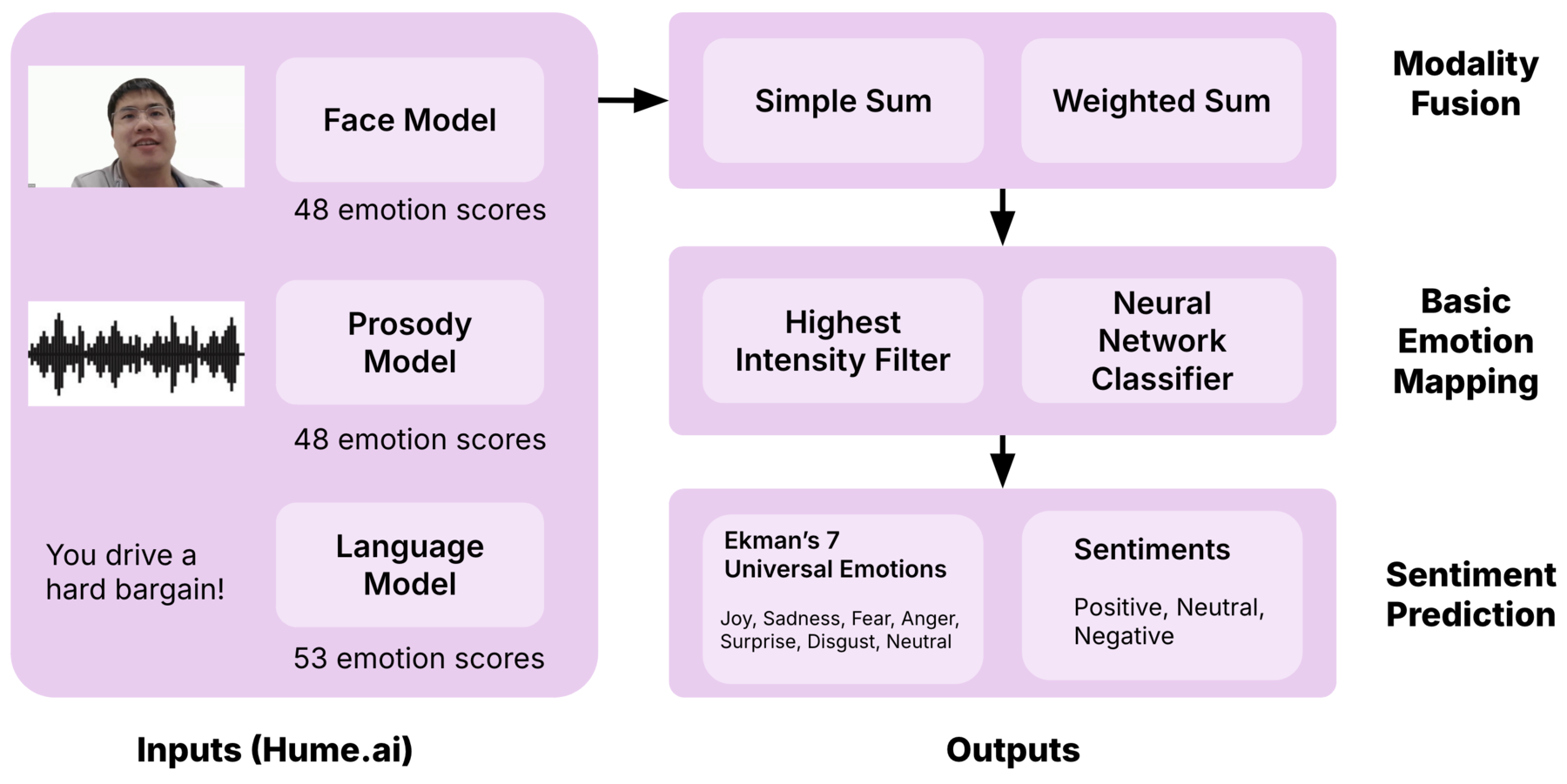
After preprocessing, we fed the video into three different models:
- Hume's facial expression model → processes facial expressions.
- Prosody model → analyzes voice tone and pitch.
- Language model → predicts sentiment based on text.
Each model operates at a different temporal frequency:
- Facial expression model: Uniformly samples one in every eight frames to analyze complex emotions.
- Prosody model: Analyzes each sentence and provides one sentiment annotation per video.
- Language model: Generates a sentiment prediction for each word.
To synchronize these different time scales, we chose the sentence level as the universal frame for sentiment labeling:
- Facial expression sentiment labels were aggregated for all frames within a sentence's time range.
- Word-based sentiment intensities were averaged across the words in each sentence.
- Prosody did not require averaging, since it already provided one label per sentence.

Modality Fusion
Feature extraction yielded three sets of predictions:
- Language-based predictions (53 emotions, each with intensity scores).
- Prosody-based predictions (48 emotions, each with intensity scores).
- Facial expression-based predictions (48 emotions, each with intensity scores).
Thus, for each sentence, we obtained up to 53 complex emotions, each with three intensity scores (one per modality: face, prosody, language).
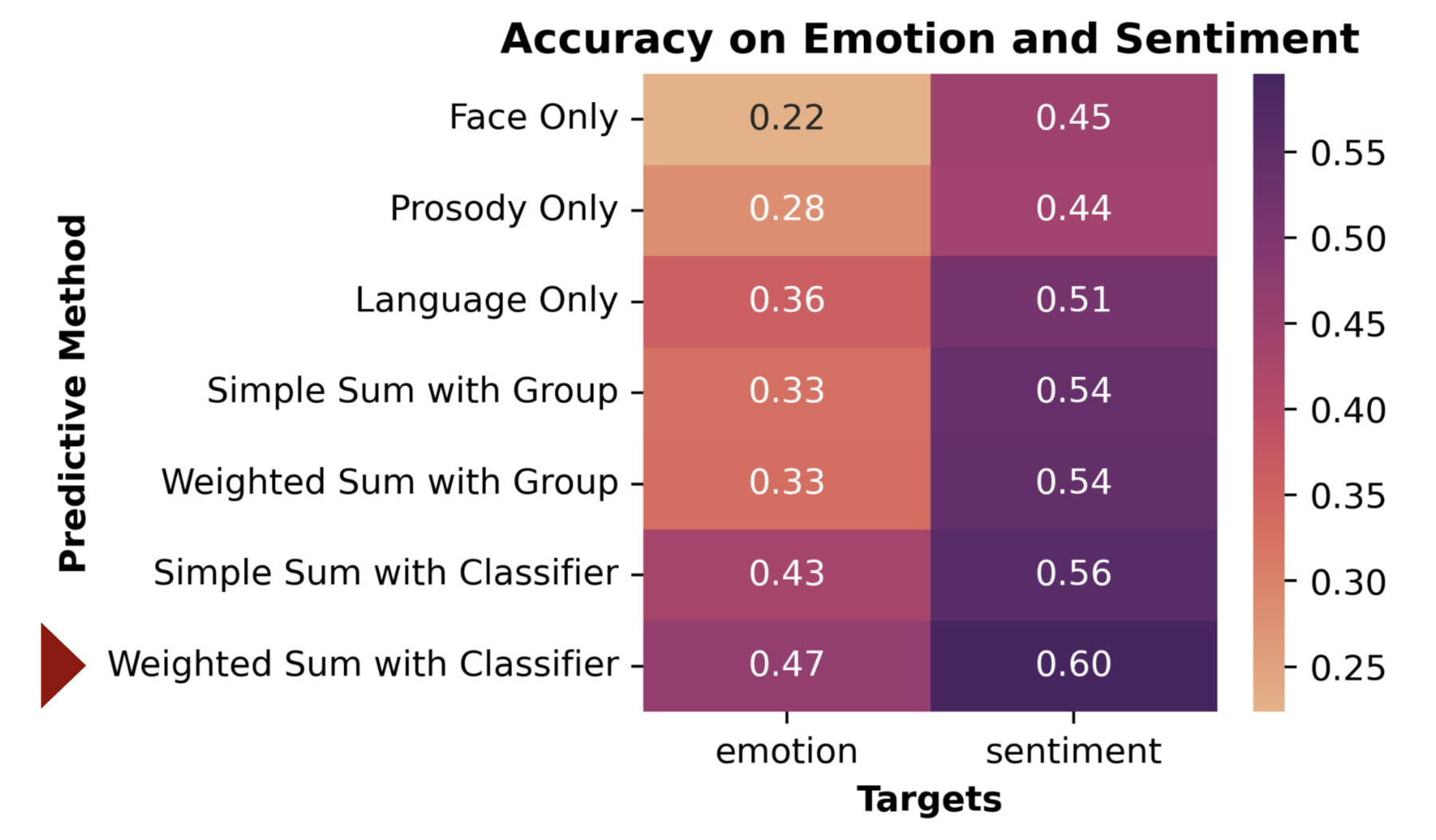
We compared multiple methods and mapped out their accuracy:
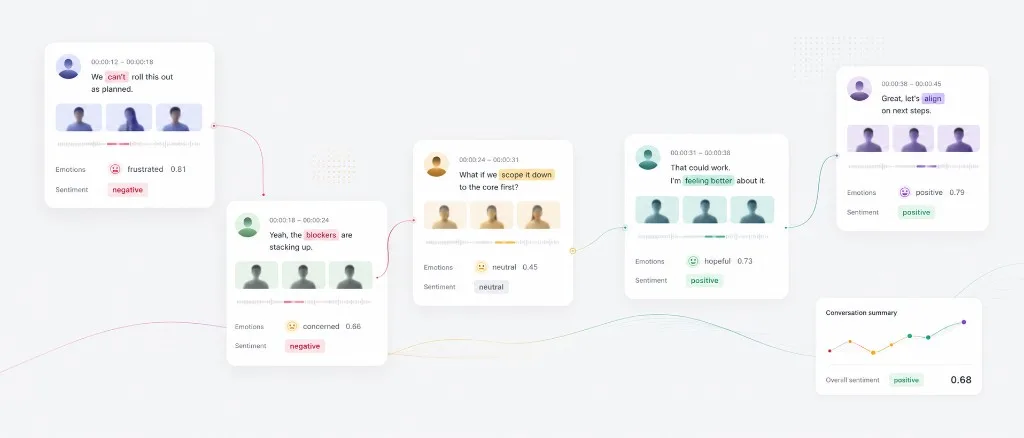
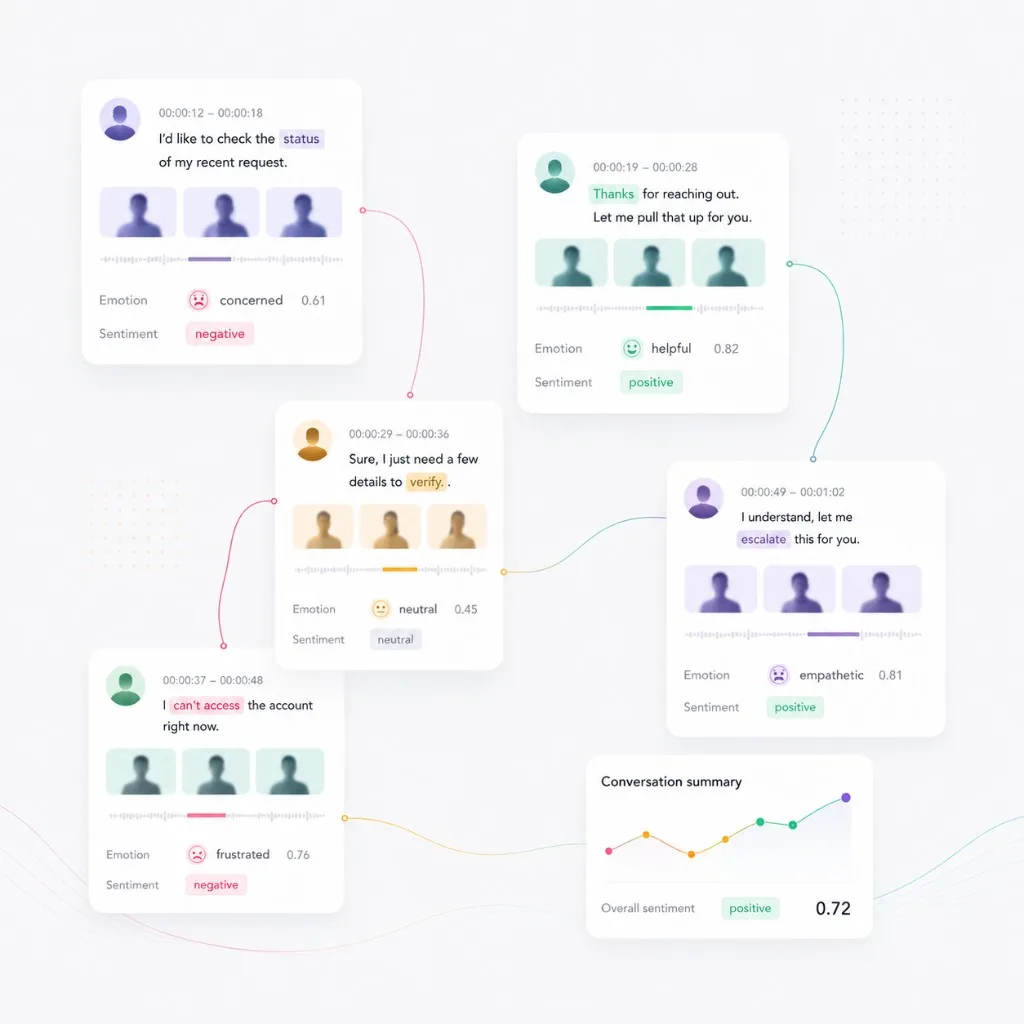
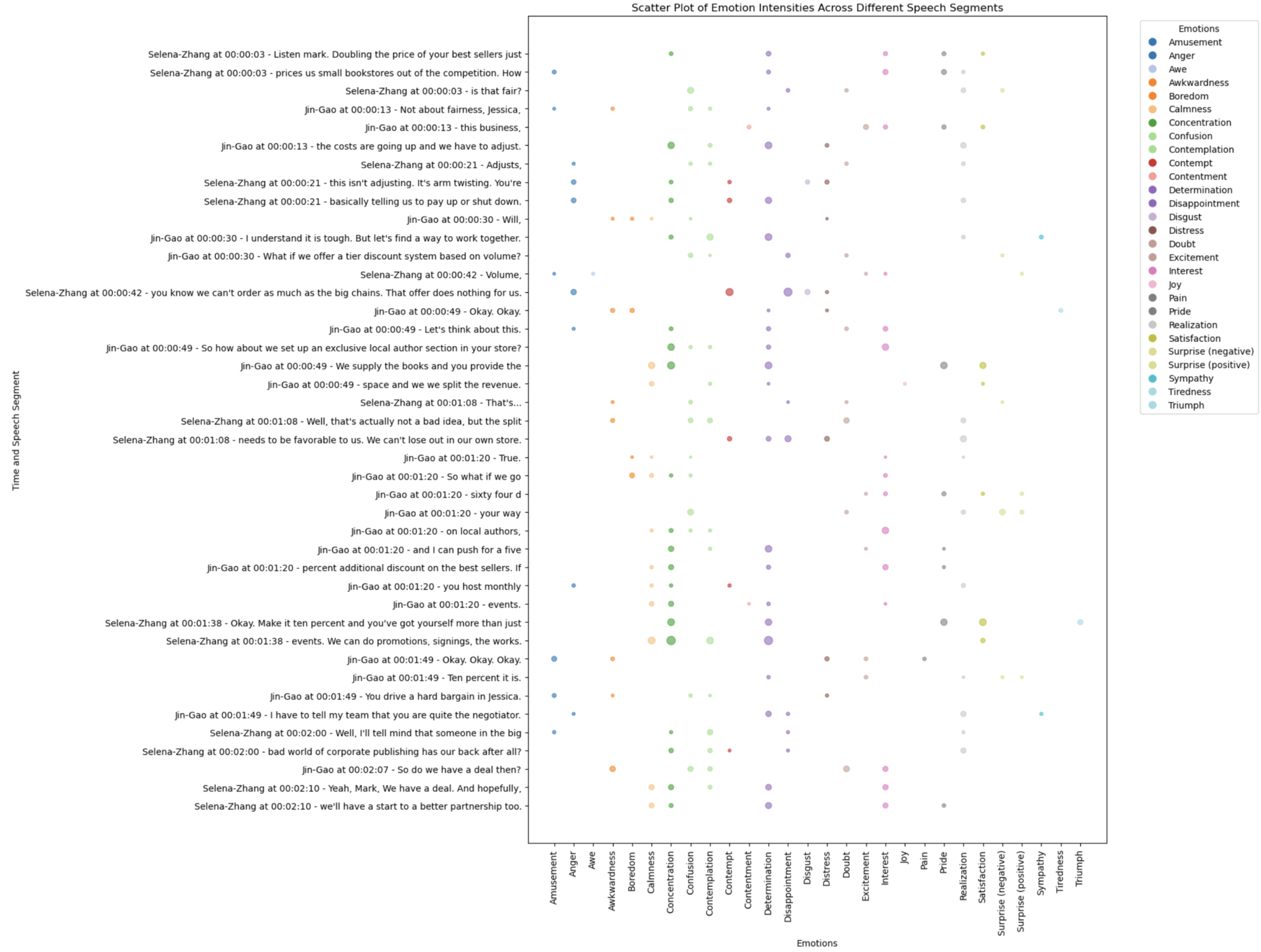
We developed an visualization interface for our test dataset and Zoom-based user studies, utilizing HTML and vanilla JavaScript. Below is a visualization of a sample dialogue:
Demo Video